
Add a Storage Location¶
Though you can learn by nominating arbitrary Zenko endpoints in a local file system, in practical applications you will need an existing account on a cloud server. This can be a public cloud, like AWS S3, or a private cloud, like Scality RING with S3 Connector.
To add a storage location:
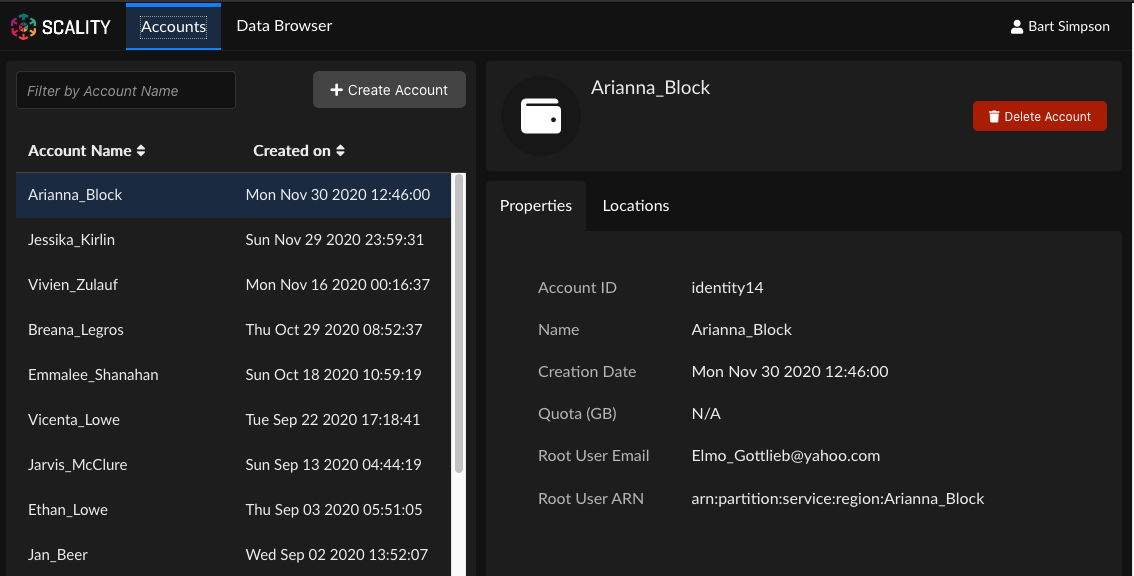
From the Accounts view, select an account name to expose account information.
Tip
If there are many accounts, you can use the field marked Search by Account Name to reduce the number of visible accounts to a manageable level.
Click the Locations tab.
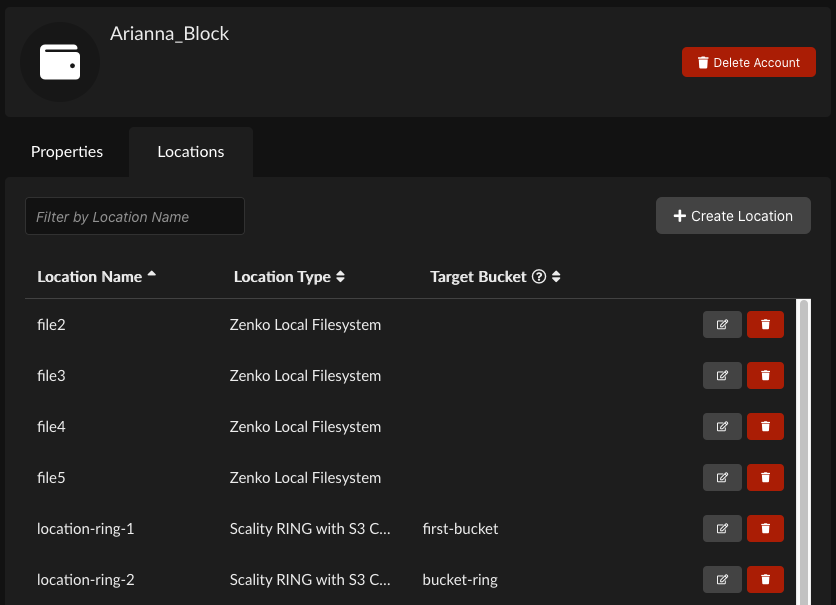
Click Create Location.
The Add New Storage Location window displays:
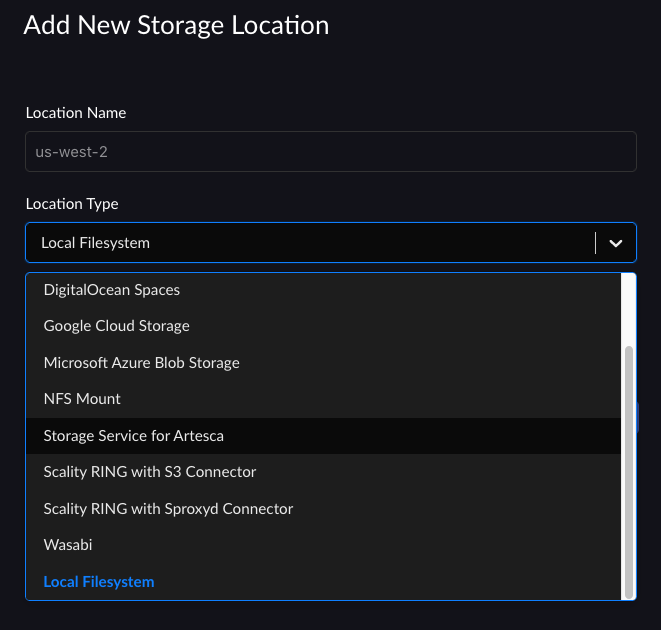
Enter a location name in the Location Name field using lowercase letters, numbers, and dashes. This is the location name that you will use in Zenko. It is not known to the cloud storage provider.
Note
Capital letters, spaces, and punctuation and diacritical marks will result in an error message.
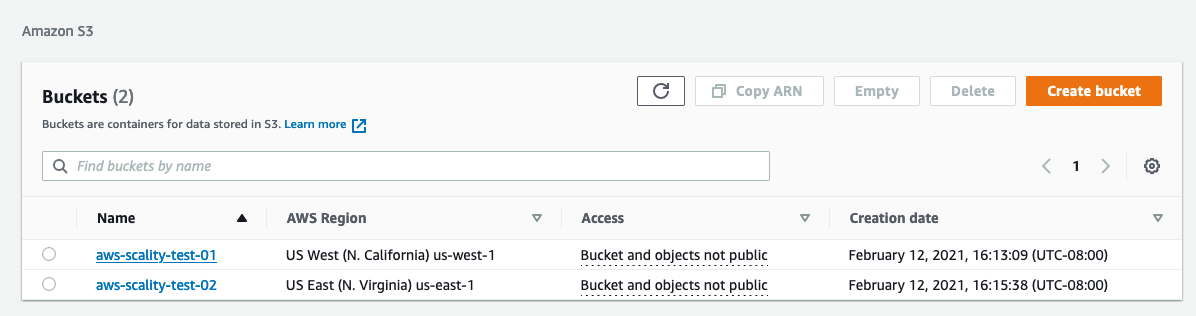
Enter the Target Bucket Name. This is the name of the bucket in the cloud location. Enter the name you see in the cloud service provider’s bucket dashboard here.
For example, in the Amazon S3 interface, this is the Name value in the Buckets window.
Select a location type from the Location Type pull-down menu. You can choose:
- Amazon S3
- Ceph RADOS Gateway
- DigitalOcean Spaces
- Google Cloud Storage
- Microsoft Azure Blob Storage
- NFS Mount
- Scality RING with S3 Connector
- Scality RING with sproxyd Connector
- Storage Service for Artesca
- Wasabi
- A Zenko local filesystem
Each storage location type has its own requirements. These requirements are detailed in Cloud Storage Locations. No security is required for the local file system, but all public clouds require authentication information.
Note
Adding a location requires credentials (an access key and a secret key). Though nothing prevents you from using account-level credentials when Zenko requests credentials for a location, it is a best practice to enter credentials specifically generated for this access. In other words, before you add a location, first create a user in that location (an AWS or S3 Connector account, for example) for the purpose of Zenko access. Give that user all and only the permissions needed to perform the desired tasks.
Tip
When configuring an S3 Connector, assign the following policy to the special Zenko-access user to ensure access to the Metadata service and the ability to perform operations on the bucket:
{ "Version":"2012-10-17", "Statement":[ { "Action":"metadata:*", "Effect":"Allow", "Resource":"*" }, { "Action":"s3:*", "Effect":"Allow", "Resource":"*" } ] }
When you have satisfied all of the target cloud location’s requirements, click Create.
Cloud Storage Locations¶
All the cloud storage services serviced by Zenko require the same basic information: an access key, a secret key, and a target bucket name. [1] The Zenko UI also presents the following requirements for each cloud storage system.
| Service | Endpoint | Bucket Match | Server- Side Encryption | Target Helper for MPU |
|---|---|---|---|---|
| Amazon S3 | - | - | Yes | - |
| Ceph RADOS Gateway | Yes | - | - | - |
| DigitalOcean Spaces [2] | Yes | Yes | - | - |
| Google Cloud Storage | - | - | - | Yes |
| Microsoft Azure Blob Storage | Yes | - | - | - |
| RING/S3C | Yes | - | - | - |
| Storage Service for Artesca | Yes | - | - | - |
| Wasabi | - | - | - | - |
These configuration options are described below.
Endpoint¶
Some service providers assign fixed endpoints to customers. Others require users to name endpoints. Services for which Zenko requests endpoint names may have additional naming requirements. For these requirements, review your cloud storage service provider’s documentation.
For Ceph RADOS Gateway endpoints, you can nominate a secure port, such as 443 or 4443. If you do not, the default is port 80. Whichever port you assign, make sure it is accessible to Zenko (firewall open, etc.).
Bucket Match¶
Zenko provides a “Bucket Match” option for Ceph RADOS Gateway. If this option is left unchecked, Zenko prepends a bucket identifier to every object in the target backend’s namespace. This enables a “bucket of buckets” architecture in which the target backend sees and manages only one large bucket and Zenko manages the namespace of the “sub-buckets.” Clicking the Bucket Match box deactivates this feature: the prepending of bucket names is defeated, and the bucket structure in the host cloud is copied identically to the target cloud.
Important
If the Bucket Match option is set, buckets in the target location cannot be used as a CRR destination. Zenko requires the bucket identifier to manage the namespace for replication.
Server-Side Encryption¶
Encryption-based transfer protocols ensure your credentials and transmitted information are secure while in transit. Amazon S3 also offers encryption and key management services to protect information stored on cloud drives. To enable server-side encryption from the Zenko UI, click Server Side Encryption when setting up an AWS S3 location. This creates a location with encryption enabled for all objects stored there. Encryption is set at the bucket level, not at the object level. Object encryption is delegated to the cloud storage system.
Server-side encryption is based on the x-amz-server-side-encryption header. Inquire with your cloud vendor to determine whether server-side encryption using x-amz-server-side-encryption is supported on their platform. A table is provided in this document, but vendors’ offerings are subject to change without notice.
If you have already created a bucket with server-side encryption enabled (SSE-S3
protocol), clicking Server Side Encryption forces Zenko to include
"x-amz-server-side-encryption": "AES256" in API calls to the cloud host (AWS
or a vendor that supports the call). If valid credentials are provided, the cloud
service provides the objects thus requested.
Target Helper Bucket for Multi-Part Uploads¶
The Google Cloud Storage solution imposes limitations on uploads that require specific workarounds. Among these is a 5 GB hard limit on uploads per command, which requires objects over this limit to be broken up, uploaded in parallel chunks, and on a successful upload reassembled in the cloud. Zenko manages this complexity, in part, by using a “helper” bucket.
Note
Google Cloud Storage also imposes a 1024-part cap on objects stored to its locations (For all other backends, Zenko caps the number of parts at 10,000). For data stored directly to GCP as the primary cloud, Zenko propagates this limitation forward to any other cloud storage services to which Google data is replicated.
Other Services: Zenko Local, RING/sproxyd, and NFS¶
Zenko Local Filesystem¶
Zenko Local Filesystem has similar authentication requirements to AWS S3, but because it is a Zenko-native filesystem, it shares authentication and related credentialing tasks, which are addressed elsewhere in the Zenko UI.
For more information, see Zenko Local.
RING with sproxyd Connector¶
The RING maintains stability and redundancy in its object data stores by way of a bootstrap list. To access a RING directly using sproxyd, you must enter at least one bootstrap server; however, more is better. This is simply a list of IP addresses for the bootstrap servers in the RING. The order of entry is not important: none enjoys a preferred position. Entries must assign a port number. If a port number is not explicitly assigned, Zenko assigns port 8081 by default. Entries can use DNS or IP address format.
NFS¶
Zenko supports out-of-band updates from NFSv3 and NFSv4 file systems. Zenko replicates data from NFS servers to cloud storage services using scheduled cron jobs.
Note
For NFS mounts, Zenko cannot perform data PUT transactions. In other words, data can be written directly to NFS for Zenko to replicate to other backends, but cannot be written to Zenko to replicate to NFS.
Configuring NFS requires you to specify the transfer protocol (TCP or UDP), NFS version (v3 or v4), the server location (IP address or URI), export path (the path to the NFS mount point on the server), and the desired NFS options (rw and async are the default entries).
AWS¶
Zenko can ingest metadata out of band from AWS in much the same way it can ingest out-of-band updates from NFS mounts. AWS metadata is ingested in an initial setup, then changes are mapped via a regularly scheduled cron job. Zenko develops its own namespace for the Amazon bucket and can perform metadata-related tasks (CRR, metadata search, lifecycle management, etc.) on targets in the AWS bucket using this namespace.
| [1] | Microsoft’s setup procedure is functionally identical to that of AWS S3. However, the Microsoft terms, “Azure Account Name” and “Azure Access Key” correspond, respectively, to the AWS terms “Access Key” and “Secret Key.” Do not confuse Amazon’s “access key” (a public object) with Microsoft’s “access key” (a secret object). |
| [2] | DigitalOcean uses different nomenclature (“Space Name” instead of “bucket name,” for example) but its constructs are functionally identical to Amazon S3’s. |




